
|
最近研究python,有點進展,雖然因為這個作品沒把該做的事情做好,找到時間就來研究。我想要做一個可以截取google搜尋結果的程式,最大的麻煩是html這個結構,剛開始我好不容易找到google搜尋結果的標題藏在html的哪一個tag,發現藏在'div'標籤裡,class類別是"BNeawe vvjwJb AP7Wnd"。這是我的第一個版本,我將它命名為『google_search v1』。
以下這個程式,按下三角形,就可以跑了,剛開始會出現一堆字,那是在載入python的模組。
剛開始會顯示 搜尋: 你只要打出你要搜尋的東西就可以了。
不過沒有連結的搜尋結果有什麼用呢,於是我想了很久,運用了最基礎的if判斷式,判斷哪裡有網址就印出來,不過出現一大堆的網址,我想到說搞不好網址會跟標題,放在同一個地方,果然有找到,所以這次會印出標題和網址。我加入了一項功能是可以無限次搜尋,不用一直重啟程式,這次的程式名稱是『google_search v1.2』,呈現為:
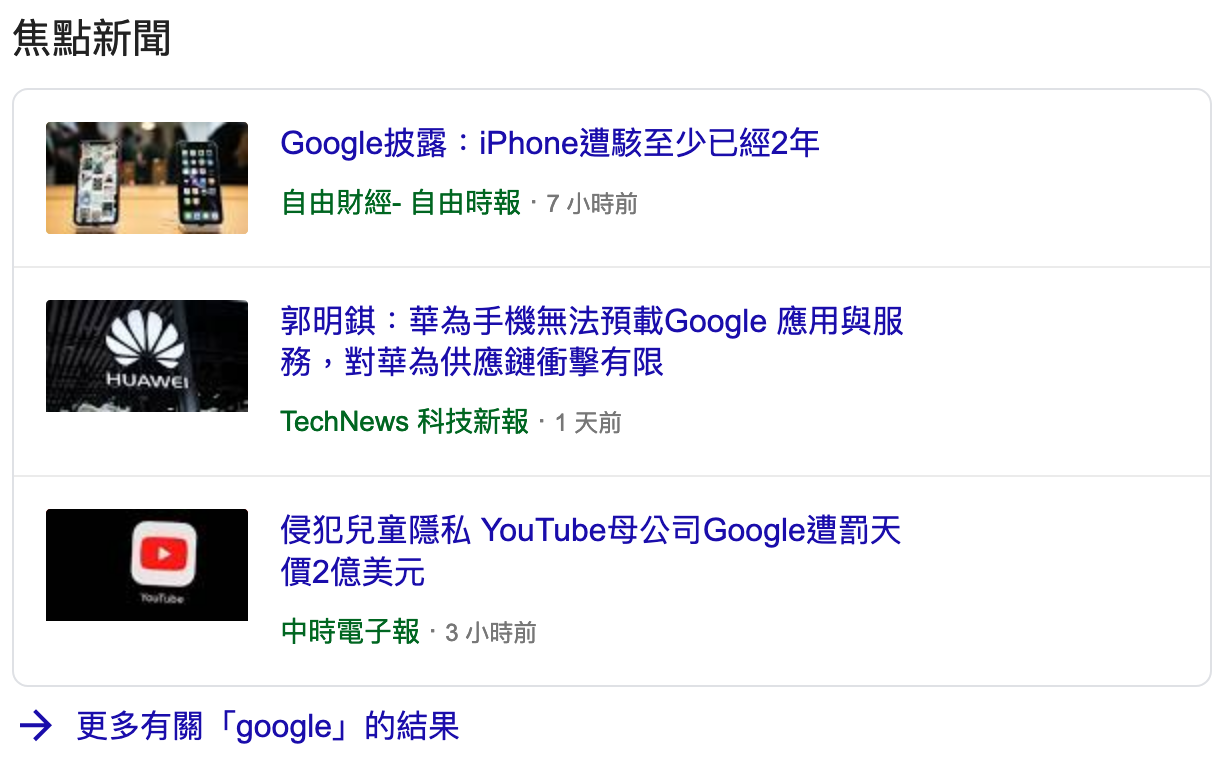
後來我發現搜尋一些東西會出現新聞、影片或是圖片,我決定把它用另一種方式解析。這次的版本為google_search v1.3
有興趣的歡迎下載python(點我去官網下載)
並且下載我的程式(點我下載)
結果如下(mac):
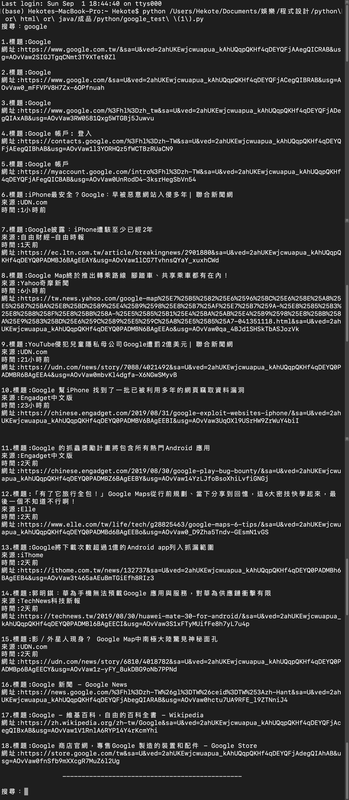
程式碼如下:
import requests
from bs4 import BeautifulSoup while True: #choose = input("使用google搜尋引擎輸入g\n使用yahoo搜尋引擎輸入y\n如果要使用同樣的搜尋引擎按下enter\n\t\t-----------------------------------------------\n") #if choose == "g": #print("google搜尋引擎") search = input("搜尋:") google = requests.get("https://www.google.com/search?q="+search) res = google.text soup = BeautifulSoup(res,"html.parser") a_tag = soup.find_all('a') #,class_="BNeawe vvjwJb AP7Wnd" b_tag = soup.find_all('div') print() x = 1 r = 1 for tag in a_tag: b = tag.find("div") if "url" in tag.get("href"): if tag.find("div"): if b.string == None: span_tag = tag.find("span",class_="rQMQod Xb5VRe") div_tag = tag.find("div",class_="BNeawe tAd8D AP7Wnd") print(x,".標題:",span_tag.text,sep="") print("來源:",div_tag.string.replace("\n","\n時間:").replace(" ",""),sep="") print("網址:",tag.get("href")[7:],"\n",sep="") else: print(x,".標題:",b.string,sep="") print("網址:",tag.get("href")[7:],"\n",sep="") x += 1 print("\t\t-----------------------------------------------\n") |
 RSS 訂閱
RSS 訂閱